I wanted to explore a bit about the power consumptions of CPEs in Belgian ISPs. This blogpost is not to be considered research-grade, it’s more a hobbyist’s peak into the power consumption of the equipment.
My main questions were: is there a significative power consumption difference between ISPs (inside consumer’s homes). And more importantly: is there a “hidden” cost behind some ISP. And finally, does the network usage impact the power consumption.
I switched ISPs 3 times in a row, and I give here a graph (taken from Home Assistant which is recording the measures from a TP-Link P110 plug) and a CSV file for the same period.
Before switching to Orange, I captured the consumption of Voo(Cable/Docsis) for a week. The amplifier and modem ensemble consumes around 20.2 watts (note the Y axis, this graph is actually a straight line).
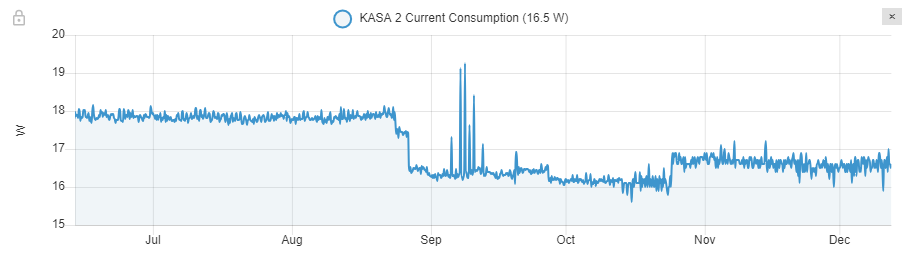
I stayed at Orange (Cable/DOCSIS) for about 6 months. The consumption includes the mandatory amplifier and the modem in bridge mode. Note that the amplifier is the same as Voo. The Wi-Fi is deactivated. It seems some update from Orange impacted the consumption, which is now around 16.8 Watts. It is a 3 Watts improvement over Voo, which, for a year represents 26kWh, so roughly 10€ in electricity.
I have no explanation for the increase in power at the end of October (another update?). Similarly there are a few spikes in September, it could be false positives I would not make conclusions based on that. This is not related to the traffic pattern, because day-to-day it’s the same power consumption. I tried to launch a speedtest and observe the instantaneous consumption and I couldn’t spot any difference.
Proximus Fiber
I then switched to Fiber with Proximus, as soon as I could. The connection is much faster: 500Mbps symmetrical.
The equipment is divided in two part : the ONT which “converts” the fiber to Ethernet, and then the modem that includes a switch, WiFi and telephony.
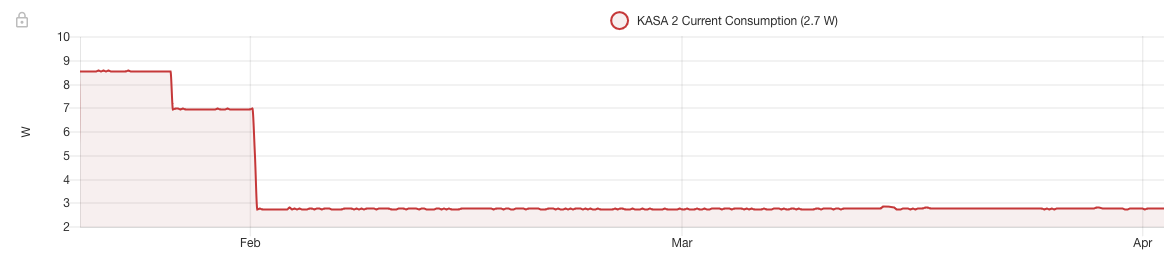
You observe 3 steps here. At the beginning I had the Modem in router mode, with Wifi activated at 8.5Watts. That’s what most people would have.
Then, the second step at 7Watts is with the Modem in Bridge mode, without WiFi. In bridge mode the modem directly give a public IP address to a single equipment connected to it. Typical for people with their own routers.
But one can go further. What I have used since February is directly the ONT at a spectacular 2,75Watts. I don’t need the modem because I don’t have fixed telephony, and don’t use WiFi in my garage. I have my own access points and want my home router anyway to handle my own ICT (I have some websites handle at home, home automation, etc).
Conclusion
First, the network usage does not impact the device’s power consumption. It is not surprising. All those modems are gigabit-capable or even more. The Orange allowance of my subscription is 150 Mbps, Voo was around the same. Hence, the modem is residing in its idle zone. With Proximus the ONT “rises” to 3 Watts during a speedtest instead of 2,75. It’s marginal.
The second question was the hidden cost. Proximus Fiber equipment drives as low as 8,5 Watts. That’s a 8,3 Watt reduction from Orange. That’s 73 kWh/year, at the Belgian average of 0,35€/kWh it’s roughly 25€ per year It’s not nothing, but it’s not high compared to the price of the subscription itself. If you have no use for the modem, then you gain 14Watts or 123kWh/year. That’s a more consequent 43€ saved.
73kWh is also 2% of the power consumption of the average Belgian household. Again, not nothing, but probably not the most urgent thing to do for the planet. It’s already much more than stupid “advices” like unplugging transformers of charging a smartphone on solar panels.
This project is part of novel CyberGalaxia project, part of CyberExcellence, and funded by the FEDER european fund.
This one-year contract will take place at Galaxia, location of many companies active in cybersecurity and space, such as Rhea, Telespazio and, of course near the ESA and the Euro Space Center. The researcher will have the opportunity to train on two demonstrators, including a cyber range.
While this contract is limited to 1 year and therefore too short to conduct a PhD, it is possible to look for further funding to conduct a PhD (typically four years in Belgium) with the ENSG. Applying as a post-doc is also possible. The salary will be matched with UCLouvain’s salary scale.
ORGANISATION/COMPANY
Université catholique de Louvain
Institute of Information and Communication Technologies, Electronics and Applied Mathematics (ICTEAM)
RESEARCH FIELD
Networking, Systems, NFV, CyberSecurity
MINIMUM REQUIRED QUALIFICATIONS
The candidate must have obtained a Master’s degree in computer science before the start date (April 2024, can be adapted). If applying as a post-doc, the same rule applies to the doctoral dissertation.
APPLICATION DEADLINE
ASAP, applications will be reviewed every two weeks until a candidate is found.
LOCATION
The applicant will share his or her time between Galaxia in Transinnes which is where the contact will be established, and a second office in Louvain-La-Neuve. The split of her/his time is to be discussed.
TYPE OF CONTRACT
Research Engineer, 1 year position, full-time
Funded as part of the CyberGalaxia FEDER project.
JOB STATUS
Full-time
HOURS PER WEEK
38
OFFER DESCRIPTION
The applicant will join the ENSG, but work partly at Galaxia in Transinnes with other members of CyberExcellence.
The candidate will build a network audit system to allow auditors to run analyses on network traffic without violating user privacy or regulations such as the GDPR. To this end, the candidate will build a verifier that ensures that the private data of users analyzed by the audit system are aggregated in a sufficient manner before being exported to the listener. For instance, the program can scan each connection to check the recipient’s secure server name (TLS SNI) but can only output a proportion of users heading to the servers of this or that service provider. The system will be based on Retina, a system previously built in a consortium including the ENSG and Stanford ESRG.
SKILLS/QUALIFICATION
Successful student
Good in the Operating System, computer systems/architecture and networking courses
Knowledge of programming in Rust is a plus, else comfortable with low level languages like C
If you have your own router, there’s no reason to use Proximus’s CPE (the Internet Box, which was called BBox in the past). Indeed, the fiber comes with two devices: the ONT, which has a fiber “in” and an ethernet port “out” (trying to speak to a large audience here), and the router itself. The router takes care of WiFi and VoIP (fix phone).
The Internet Box
A lot of people had their modem in “bridge” mode already in the past, so they’d use their own router and WiFi access point. With fiber, using the bridge mode if you don’t have telephony doesn’t make any sense, you can just get rid of the Internet Box.
The ONT : GE1 can be used directly, without the Internet Box in between
It will be the subject of another post, but the gains are substantial in term of electricity consumption. The ONT only consumes around 2.5 Watts. The Internet Box consumes an additional 6.5 Watts that can be removed. So that’s 56kWh, or around 20euros of electricity per year. It also slows the down the latency by something around 1.5ms, which, knowing the latency with fiber is around 6.7ms without the box is quite consequent.
WAN Connectivity
The following explains how to get connectivity when directly connecting your router to the ONT. This tutorial assumes Ubuntu 22.04. I use ifupdown, like old people instead of the novel netplan, on 22.04 it must be installed:
#/bin/bash
ip link add link enx00e04c680a48 name internet0 type vlan id 20
exit 0
The exit 0 part is an awful trick to avoid failing if the vlan is already created (for instance if you do sudo service networking restart).
That’s it. If you restart the networking service, you’ll get both an IPv4 address and an IPv6 /64 range. Interestingly, you get the /64 prefix through RA, but for your local network, you may use DHCPv6 to get a /56 range. It’s quite practical because you don’t have to subdivide the /56 range yourself.
For IPv4, it’s just standard NAT. For IPv6 you must enable IPv6 prefix delegation.
First, enable IP forwarding. If you have a firewall, remember to allow the FORWARDING traffic.
/etc/sysctl.conf
#Uncomment the following lines
net.ipv4.ip_forward=1
net.ipv6.conf.all.forwarding=1
To enable the NAT, either you directly add an IPTables rules somewhere:
sudo iptables -A POSTROUTING -s 192.168.1.0/24 -o internet0 -j MASQUERADE
Or, you add the following line for the UFW firewall, in /etc/ufw/before.rules:
-A POSTROUTING -s 192.168.1.0/24 -o internet0 -j MASQUERADE
In both cases, change your local network range according to your setup.
IPv6 Prefix Delegation
You have to add the following script found at https://wiki.debian.org/IPv6PrefixDelegation in /etc/dhcp/dhclient-exit-hooks.d/prefix_delegation:
# This script assigns a delegated IPv6 prefix obtained via DHCPv6 to another interface
#
# Usage: This scrips is designed to be called from dhclient-script (isc-dhcp-client).
#
# LOCATION: /etc/dhcp/dhclient-exit-hooks.d/prefix_delegation
# RECOMMENDED PACKAGES: ipv6calc
# CONFIGURATION OPTIONS
# Define the interface to which a delegated prefix will be assigned
# This must not be the same interface on which the prefix is learned!
IA_PD_IFACE="br0"
# Provide a space separated list of services that need to be restarted or reloaded after a prefix change
# Services must be controllable via systemd's systemctl, the default action is restart
# Service names may be followed by a colon and action name, to override the default action
# Supported actions are: restart and reload
# Example: IA_PD_SERVICES="shorewall6:reload dnsmasq"
IA_PD_SERVICES=""
# Define the location of the ipv6calc executable, if installed
# If this is empty or no executable file, no EUI-64 based IPv6 address will be calculated for the interface set in IA_PD_IFACE; instead, a static interface identifier (::1) will be appended to the prefix
# Example: IA_PD_IPV6CALC="/usr/bin/ipv6calc"
IA_PD_IPV6CALC=""
# Set to yes to make logging more verbose
IA_PD_DEBUG="yes"
# END OF CONFIGURATION OPTIONS
logger -t "dhcpv6-pd" -p daemon.info "DHCPv6-PD is running"
fn_calc_ip6addr() {
[ -z "$1" ] && return
local ia_pd_mac
local ia_pd_addr
[ -e "/sys/class/net/${IA_PD_IFACE}/address" ] && ia_pd_mac="$(cat /sys/class/net/${IA_PD_IFACE}/address)"
if [ -n "$ia_pd_mac" ] && [ -n "$IA_PD_IPV6CALC" ] && [ -x "$IA_PD_IPV6CALC" ]; then
[ "$IA_PD_DEBUG" = "yes" ] && logger -t "dhcpv6-pd" -p daemon.debug "Debug: Determined MAC address $ia_pd_mac for interface $IA_PD_IFACE."
ia_pd_addr="$("$IA_PD_IPV6CALC" -I prefix+mac -A prefixmac2ipv6 -O ipv6addr "$1" "$ia_pd_mac")"
fi
if [ -z "$ia_pd_addr" ]; then
[ "$IA_PD_DEBUG" = "yes" ] && logger -t "dhcpv6-pd" -p daemon.debug "Debug: Failed to calculate EUI-64 based IPv6 address, using static client suffix ::1 instead."
echo "$1" | sed 's#::/#::1/#'
else
echo "$ia_pd_addr"
fi
}
fn_restart_services() {
if [ -n "$IA_PD_SERVICES" ]; then
local pair
local action
local daemon
for pair in $IA_PD_SERVICES ; do
action="$(echo "$pair" | cut -d':' -f2)"
daemon="$(echo "$pair" | cut -d':' -f1)"
# Check if a valid action was provided or default to 'restart'
case $action in
reload) action="reload";;
*) action="restart";;
esac
# Check if daemon is active before trying to restart or reload it (avoids non-zero exit code)
if ! systemctl -q is-active "${daemon}.service" > /dev/null ; then
logger -t "dhcpv6-pd" -p daemon.info "Info: $daemon is inactive. No $action required."
continue
fi
if systemctl -q "$action" "${daemon}.service" > /dev/null ; then
logger -t "dhcpv6-pd" -p daemon.info "Info: Performed $action of $daemon due to change of IPv6 prefix."
else
logger -t "dhcpv6-pd" -p daemon.err "Error: Failed to perform $action of $daemon after change of IPv6 prefix."
fi
done
elif [ "$IA_PD_DEBUG" = "yes" ]; then
logger -t "dhcpv6-pd" -p daemon.debug "Debug: No list of services to restart or reload defined."
fi
}
fn_remove_prefix() {
[ -z "$1" ] && return
[ "$IA_PD_DEBUG" = "yes" ] && logger -t "dhcpv6-pd" -p daemon.debug "Debug: Old prefix $1 expired."
if [ "$(ip -6 addr show dev "$IA_PD_IFACE" scope global | wc -l)" -gt 0 ]; then
logger -t "dhcpv6-pd" -p daemon.info "Info: Flushing global IPv6 addresses from interface $IA_PD_IFACE."
if ! ip -6 addr flush dev "$IA_PD_IFACE" scope global ; then
logger -t "dhcpv6-pd" -p daemon.err "Error: Failed to flush global IPv6 addresses from interface $IA_PD_IFACE."
return
fi
# Restart services in case there is no new prefix to assign
[ -z "$new_ip6_prefix" ] && fn_restart_services
elif [ "$IA_PD_DEBUG" = "yes" ]; then
logger -t "dhcpv6-pd" -p daemon.debug "Debug: No global IPv6 addresses assigned to interface $IA_PD_IFACE."
fi
}
fn_assign_prefix() {
[ -z "$1" ] && return
local new_ia_pd_addr
new_ia_pd_addr="$(fn_calc_ip6addr "$1")"
if [ -z "$new_ia_pd_addr" ]; then
logger -t "dhcpv6-pd" -p daemon.err "Error: Failed to calculate address for interface $IA_PD_IFACE and prefix $1"
return
fi
[ "$IA_PD_DEBUG" = "yes" ] && logger -t "dhcpv6-pd" -p daemon.debug "Debug: Received new prefix $1."
# dhclient may return an old_ip6_prefix even after a reboot, so manually check if the address is already assigned to the interface
if [ "$(ip -6 addr show dev "$IA_PD_IFACE" | grep -c "$new_ia_pd_addr")" -lt 1 ]; then
logger -t "dhcpv6-pd" -p daemon.info "Info: Adding new address $new_ia_pd_addr to interface $IA_PD_IFACE."
if ! ip -6 addr add "$new_ia_pd_addr" dev "$IA_PD_IFACE" ; then
logger -t "dhcpv6-pd" -p daemon.err "Error: Failed to add new address $new_ia_pd_addr to interface $IA_PD_IFACE."
return
fi
fn_restart_services
elif [ "$IA_PD_DEBUG" = "yes" ]; then
logger -t "dhcpv6-pd" -p daemon.debug "Debug: Address $new_ia_pd_addr already assigned to interface $IA_PD_IFACE."
fi
}
# Only execute on specific occasions
case $reason in
BOUND6|EXPIRE6|REBIND6|REBOOT6|RENEW6)
# Only execute if either an old or a new prefix is defined
if [ -n "$old_ip6_prefix" ] || [ -n "$new_ip6_prefix" ]; then
# Check if interface is defined and exits
if [ -z "$IA_PD_IFACE" ] || [ ! -e "/sys/class/net/${IA_PD_IFACE}" ]; then
logger -t "dhcpv6-pd" -p daemon.err "Error: Interface ${IA_PD_IFACE:-<undefined>} not found. Cannot assign delegated prefix!"
ls -al /sys/class/net/
else
# Remove old prefix if it differs from new prefix
[ -n "$old_ip6_prefix" ] && [ "$old_ip6_prefix" != "$new_ip6_prefix" ] && fn_remove_prefix "$old_ip6_prefix"
# Assign new prefix
[ -n "$new_ip6_prefix" ] && fn_assign_prefix "$new_ip6_prefix"
fi
fi
;;
esac
Don’t forget to change the few first configuration lines. My LAN network is “br0” because I use a bridge over multiple interfaces.
That script will get the DHCP-assigned range and add it to the LAN interface. We still need to enable RADVD to advertise the prefix on the lan:
interface br0 # LAN interface
{
AdvManagedFlag off; # no DHCPv6 server here.
AdvOtherConfigFlag off; # not even for options.
AdvSendAdvert on;
AdvDefaultPreference high;
AdvLinkMTU 1280;
prefix ::/64
{
AdvOnLink on;
AdvAutonomous on;
};
};
And that’s all. Note we don’t need wide-dhcp-client anymore, which anyway has a blocking bug and seems to be unmaintained. dhclient is able to do everything we need, given the script for prefix delegation.
I’m happy to share the exciting news that my project for the Incentive Grant for Scientific research (MIS) from our national fund for 470K€ (one PhD, one post-doc and equipment) was accepted, while a PhD student of our team, Clément Delzotti got his 4-year PhD funded by FNRS FRIA too!
The MIS project “DHNET: The Disaggregated Host Networking paradigm to enable particle-to-particle streams” is a more fundamental project looking beyond the current design of the Internet, to enable more efficient communications. The Internet is built around the idea monolithic computers are communicating. Each computer gets an address, and communicate together as a whole. As physician refined the model of atoms in particles, the Internet needs to be redesigned to look inside computers. Components, particles, like GPU, CPU caches, TPUs, network interfaces need to communicate directly together as computers are not monolithic devices anymore, but an interconnect of many components and memory domains. Why would a transfer, say a picture generated by a cloud gaming GPU go through a CPU, a proxy, a load balancer while it could be sent through a direct path to the consumer’s screen? In practice we will use the newfound programmability of networks with programmable switches and SmartNICs to direct the data to the right particle.
The FRIA grant obtained by Clément Delzotti builds upon data acquired at the lab showing network I/O intensive application can sustain a good quality of service while achieving a 8X energy reduction by spreading differently the traffic on multiple cores and tuning frequency appropriately. The project aims at building an energy-aware data center load-balancer to reduce energy waste.
Therefore, expect a new PhD and post-doc position to open soon! The post-doc one is already open, just consider it can be extended 😉
You can use mine as you wish, I tried to find the original authors and the appropriate license whenever I could. Don’t hesitate to send me your own.
NAND SSD (inspired from https://commons.wikimedia.org/wiki/File:NAND-ssd.svg, CC )RAM Module ( inspired from https://fr.m.wikibooks.org/wiki/Fichier:Ram-module.svg CC)CPU (absed on https://commons.wikimedia.org/wiki/File:Abstract_i7_CPU_icon.svg, CC)DPI (unsure but I think it’s my own. Anyway it’s standard)Fast (own)GPU (own)IPSEC (unsure)Load Balancer (unsure)Monitoring, monitor, measurements (unsure)Mellanox NIC (not SVG, Mellanox)100G NIC (inspired from the above, consider my own I guess)Router (unsure, but this is quite sandard…)VLAN (own)
I’m pleased to announce Retina has been accepted to appear at SIGCOMM at the end of the month ! It is the result of a pleasant collaboration with Gerry Wan, Fengchen Gong and Zakir Durumeric from Stanford.
Retina enables high-speed network forensics by building a binary tailored to a specific experiment written in Rust. It provides convenient filtering capabilities to easily answer questions such as “Is the TLS SNI really random?” or “How many TLS handshake are destined to Netflix?”. Tested at up to 160Gbps with a commodity server on a Stanford traffic TAP, it supports 5-100x higher traffic rates than standard “bloatware” IDSes.
paper ; github ; the video will follow after SIGCOMM
In the Linux kernel, Block I/O request are asynchronous. It means that when you call submit_bio(READ/WRITE, bio); or generic_make_request(…), the function will (most probably) return directly, and of course, the read is not done. So after calling bio_submit(READ…); you absolutely cannot read the content of a page added by bio_add_page().
So, how to know when it is finished? You have to use bio->bi_end_io pointer function. You have to set this pointer to a function which will be called when the read has been done.
[code lang=”c”]void myReadIsFinished(struct bio* bio, int error) {
//Read is finished, do something with the bio content
}
When implementing a device driver or a MD device which can receive Block I/O (struct bio in the kernel), you can receive BIO of nearly any size, with any number of segments (segments are discontinued parts of a common buffer, defined in a bio request). You may want to limit :
– The number of segments you can receive with
[code lang=”c”]blk_queue_max_segments(queue, X);[/code]
Where X is the number of segments per struct bio
– The maximal size of the request :
[code lang=”c”]blk_queue_max_hw_sectors(queue, Y);[/code]
Where Y is the maximal size in sectors
For a md device, the queue can be recovered with mddev->queue
The combination of the two allows to limit ensure that all bio request have always maximum X segments for a maximal size of Y sectors.
It is used in raid0 with Y=mddev->chunk_sectors to ensure that no request is bigger than one chunk, so any request cross at most one chunk boundary. And with X=1, it allows to use the bio_split function to split a request which would span on the two sides of a chunk boundary.
If you’ve got your mails under a text format in a folder (like the unix Maildir) you can use this command to extract the e-mails with a 550 return error.
The first command in the pipe, cat, send all files content to the next command in the pipe : grep. Grep is removing everything except what is an adress, and only if it is followed by “host * said * 55[0-9] ” where * can be everything and [0-9] is a number between 0 and 9. We also use the –text parameter because some mails could contain binary data.
As grep give you the mail separated by new line, and an sql command takes a list of strings separated by comma, you can copy the list in gedit or notepad++ and use search->replace to change them in the format ‘mail1’, ‘mail2’, … You have to put “(.*)” in the search field, “‘\1’,” in the replace by field, and select “regular expression”. You then place the result in the parenthesis after IN, in SQL command below :
UPDATE contact SET mail='' WHERE mail IN ('bad@hotmail.com', 'error@mail.com')