Georgios P. Katsika, Tom Barbette, Dejan Kostić, JR. Gerald Q. Maguire, Rebecca Steinert
The NSDI version of Metron supported the integration of blackbox network functions (NFs) using ring buffers. This choice limited Metron’s applicability, as real networks might contain hardware blackboxes (also known as middleboxes) or closed-source blackbox binaries running inside virtual machines (VMs) or containers. In this extended journal version published in ACM Transaction on Computer Systems, we put special effort on integrating these important blackbox types into Metron, while maintaining Metron’s hardware-level performance.
This integration was not trivial as it involved tedious low-level system aspects related to (i) efficiently dispatching packets without introducing unnecessary inter-core communication and (ii) techniques to allow high-speed service chaining. These were key principles of Metron that we wanted to maintain. Moreover, we incorporated the latest functionalities of modern 100 GbE NICs, such as single root I/O virtualization (SR-IOV) that enables physical to virtual NIC dispatching, avoiding the need for software switching. Metron instructs the physical NIC to tag the packets according to the core associated with a traffic class by the controller. The tag can then be used to dispatch packets to queues just as a Metron agent does.
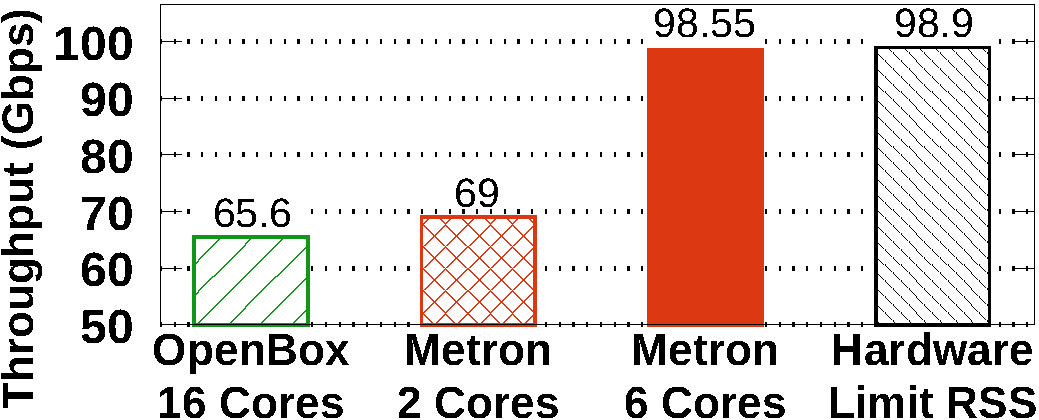
As appeared in USENIX NSDI 2018, the original Metron system demonstrated an experiment on dynamic scaling at 10 Gbps. 100 GbE deployments are becoming the new commodity. Therefore, we put substantial effort on refining Metron’s scaling algorithm. Part of this algorithm uses our new method for deriving the load of a CPU core even when this core performs NIC polling (e.g., using DPDK poll mode drivers).
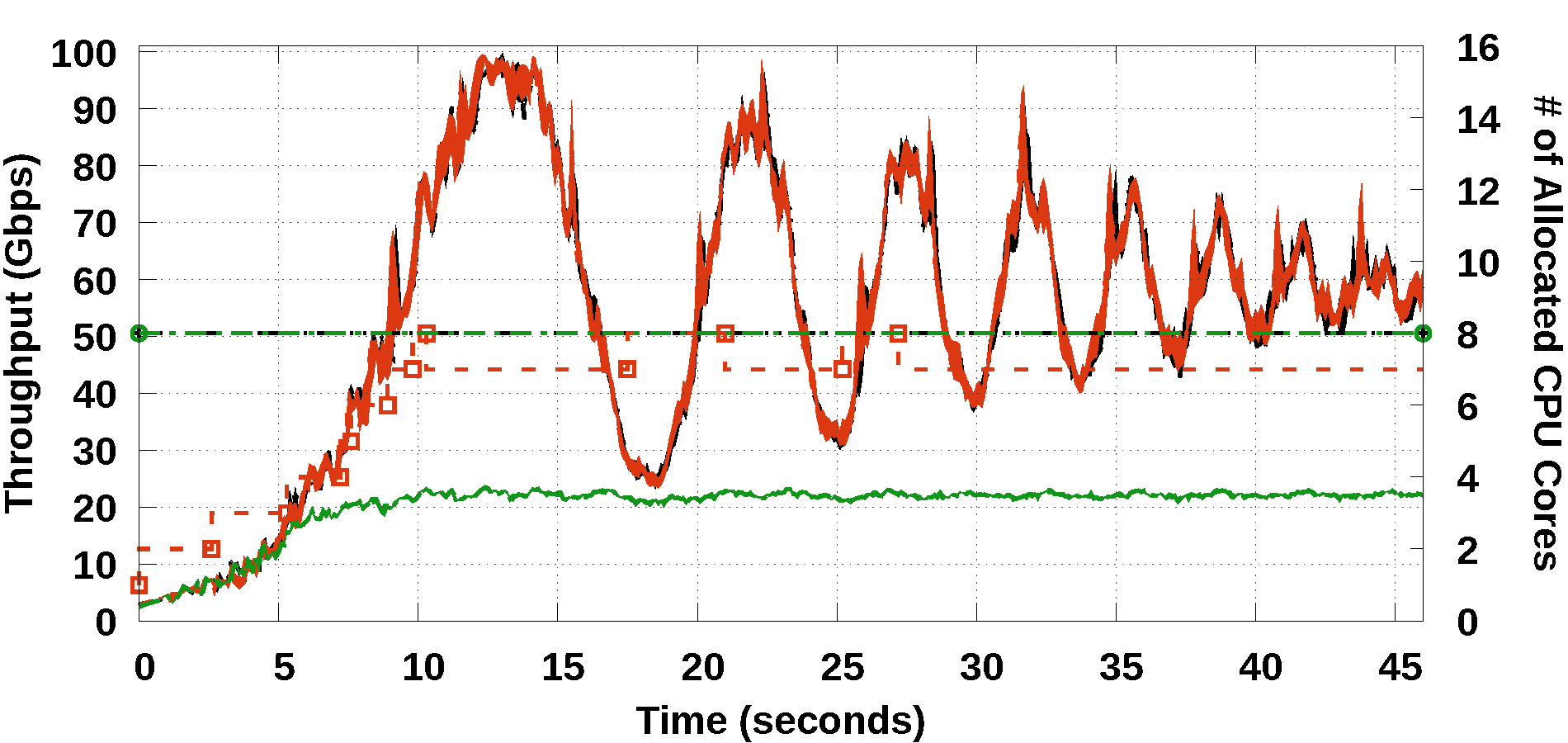
The 100 GbE testbed used in the NSDI version of Metron exhibited hardware limitations that prevented Metron from reaching line-rate performance. In this journal, we repeated the same experiment on two additional testbeds: First we upgraded the 100 GbE NICs of the original testbed (i.e., replacing the Mellanox ConnectX-4 with newer Mellanox ConnectX-5 NICs) and managed to increase the maximum throughput at 85 Gbps (76 Gbps was the previous limit). Then, we also upgraded the servers of the testbed using new workstations with Intel’s Skylake hardware architecture (the old servers used Intel’s Haswell hardware architecture) and managed to achieve line-rate 100 Gbps packet processing.
The paper also presents a dozen other novelties compared to the NSDI version, so check it out!